Build a Stable Diffusion playground app with VESSL Run and Streamlit
Learn how to quickly create GPU-accelerated AI/ML apps and inference services

Building a web-based AI services can be a challenge as the machine learning engineers who worked on the models are often unfamiliar with the infrastructure and interface layer of the app.
In this tutorial, we’ll explore how the combination of VESSL Run and Streamlit help you quickly prototype and deploy AI apps on your infrastructure without spending hours on Kubernetes and JS frameworks.
You can find the final code in our GitHub repository. You can also try out the app yourself using our quickstart command.
pip install --upgrade vessl
vessl hello
Overview
What we’ll build
In this tutorial, we are going to build a simple playground for Stable Diffusion, a text-to-image generative AI model, similar to this demo on Hugging Face Space by Stability AI, on VESSL’s managed AWS. You will also explore how you can host the app on your own cloud or on-prem. The end result will look like this.

For our model, we used the Hugging Face Diffusers library which provides a state-of-the-art pre-trained model for Stable Diffusion.
For the infrastructure layer, we are going to use VESSL Run. VESSL Run abstracts the complex compute backends required to train, fine-tune, and serve containerized AI models into a unified YAML interface. With VESSL Run, you can create GPU-accelerated compute environments for inference tasks in seconds without worrying about ML-specific peripherals like cloud infrastructures, CUDA configurations, and Python dependencies.
For the interface layer, used Streamlit. Streamlit is an open-source Python library that makes it easy to create and share custom web apps for machine learning. Here, you can see how we built our UI for the app in minutes just using Python.
The combination of VESSL Run and Streamlit removes the common bottlenecks in building AI applications and in the process separates the components and the corresponding stacks for the model, infra, and interface.
What you’ll learn
- How to quickly run and deploy computationally intensive generative AI models such as LLMs as web applications.
- How to spin up a GPU-accelerated runtime environment for training, fine-tuning, and inferencing using VESSL Run.
- How to run web-based data applications using Streamlit.
Resources
Project setup
To create your runtime, first sign up for a free VESSL account. You will receive enough free GPU credits to complete this tutorial.
When you create your account and sign in, you will get a default Organization with our managed AWS. This is where you will create a cloud runtime environment for the app. Let’s also install our Python package and set up the VESSL CLI.
# Grant access and select default organization
vessl configure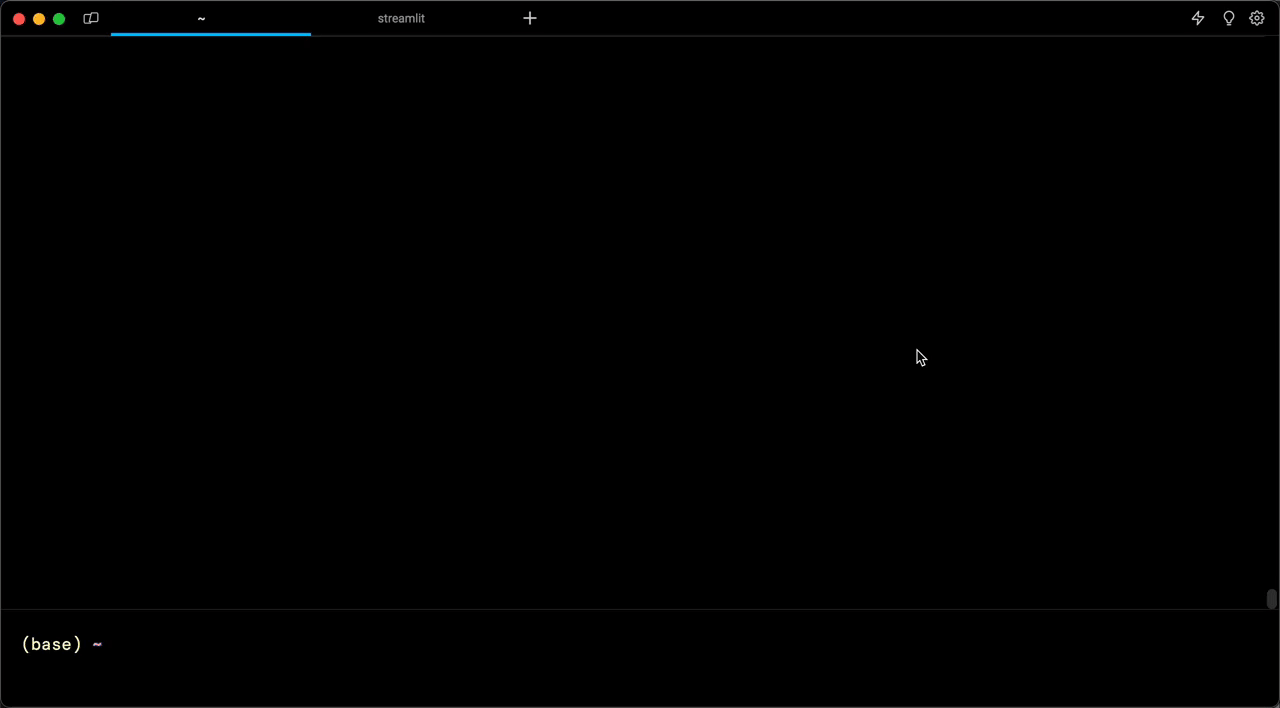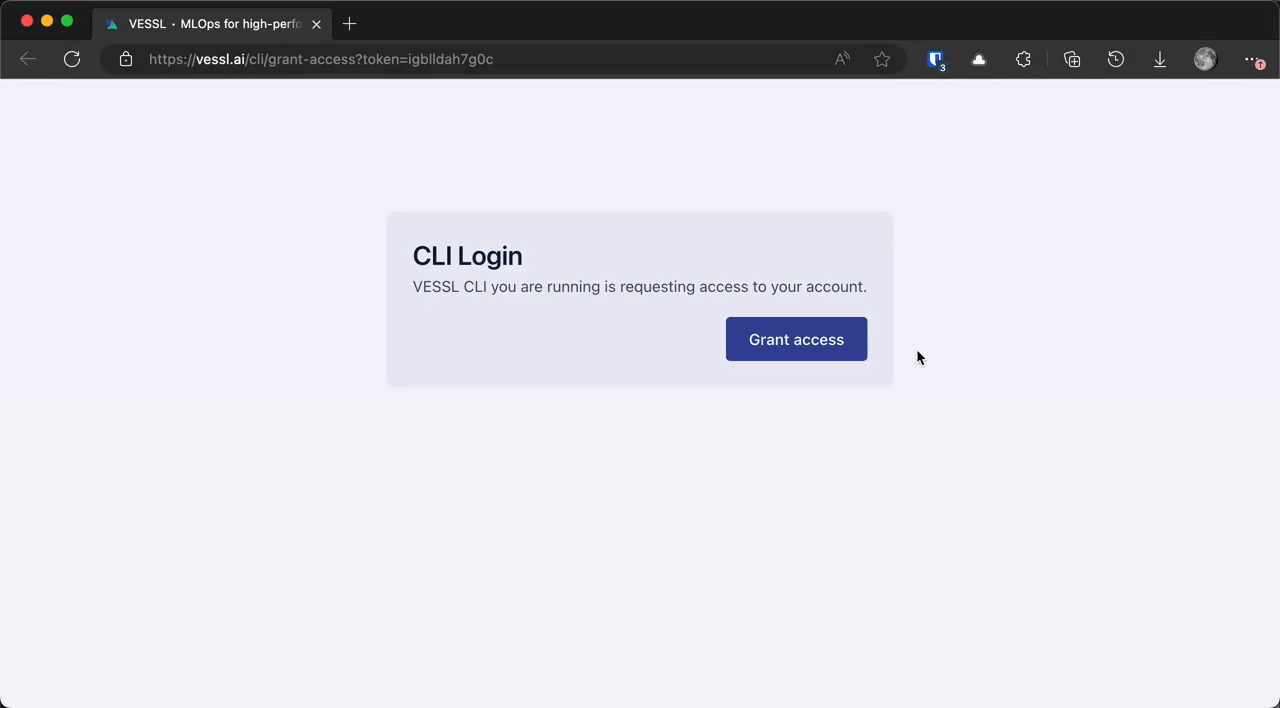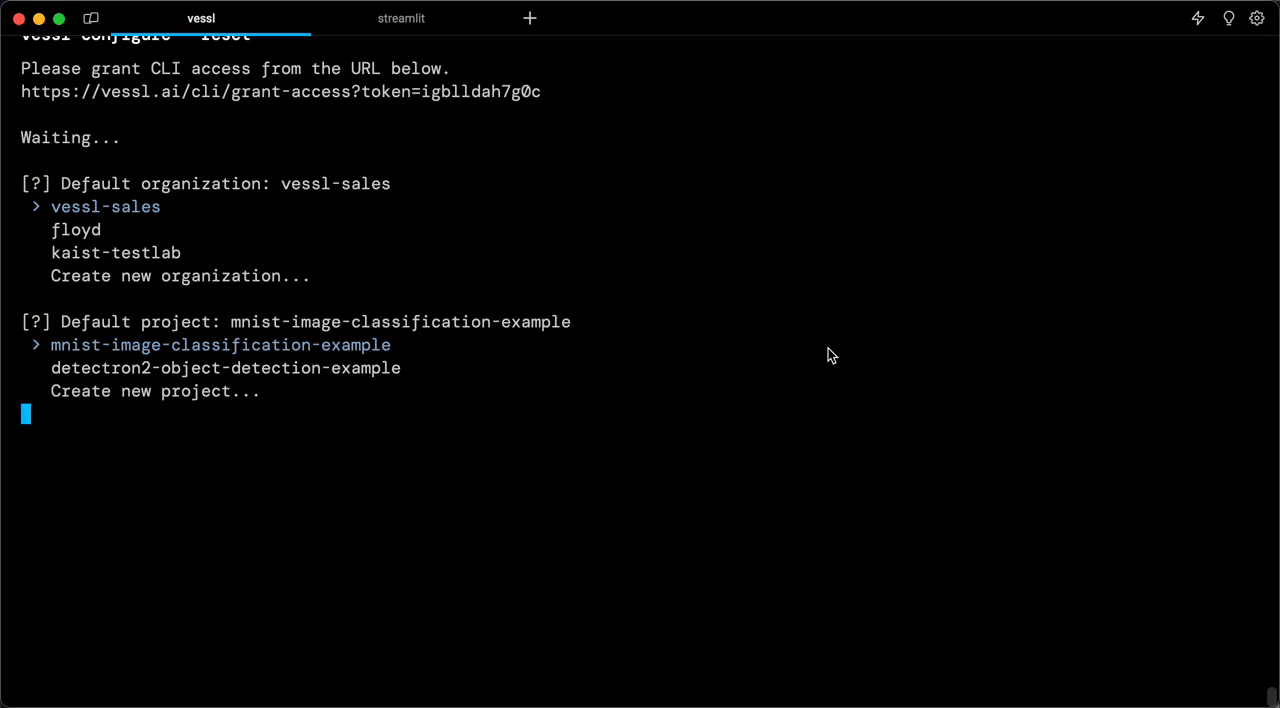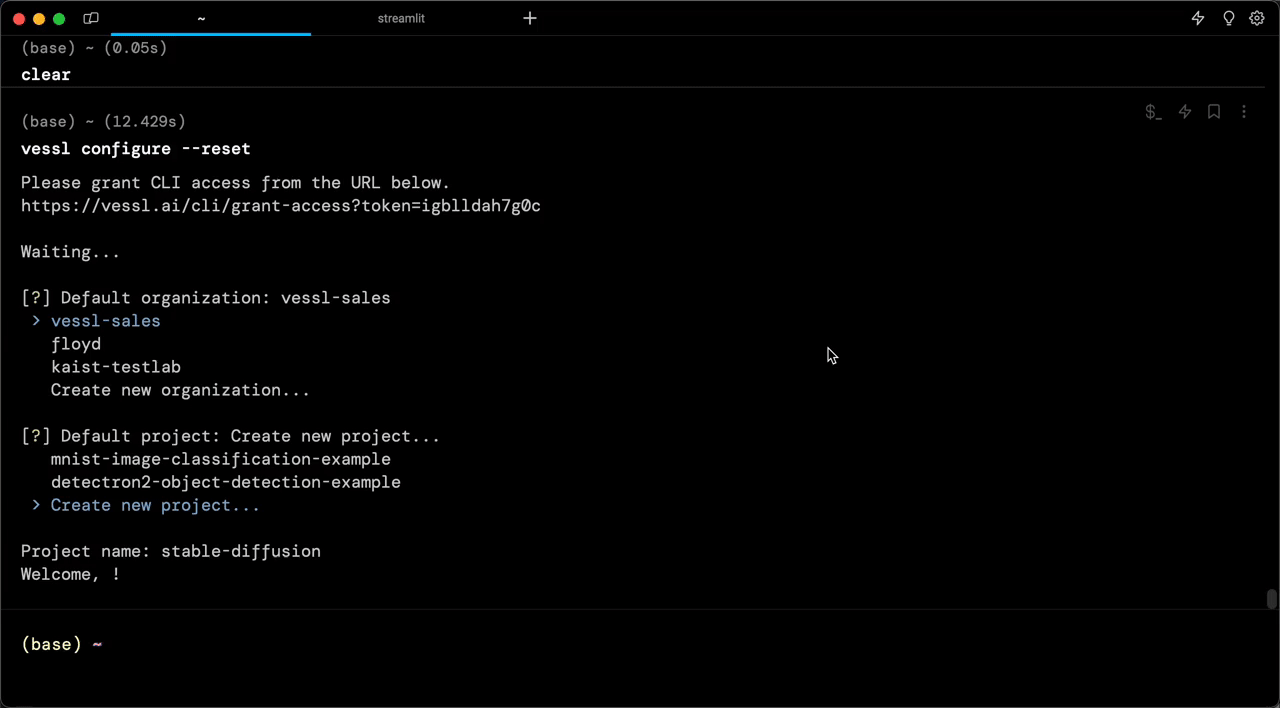
Set up a GPU-accelerated environment
With VESSL Run, setting up a runtime environment begins with defining a simple YAML definition. Whether you are training, fine-tuning, or serving, you start with the following skeleton and later add more key-value pairs.
name: # name of the model
resources: # resource specs
clusters:
accelerators:
image: # link to a Docker imageFor our Stable Diffusion app, we will initiate a p3.2xlarge instance on AWS which is equivalent to one NVIDIA V100 GPU, and use a custom Docker image we prepared for the model. Translating this into a YAML is as simple as the following.
name: stable-diffusion
resources:
clusters: aws-uw2
accelerators: v100:1
image: quay.io/vessl-ai/ngc-pytorch-kernel:22.12-py3–202301160809With this custom Docker image, the app is ‘run-proof’ regardless of where you run the app. Later, we will explore how you can use the same Docker image to run the app on your cloud or on-prem GPUs just by editing the value for resources, without having to spend hours PyTorch and CUDA versions.
Since what we created is essentially a Kubernetes-backed virtual container, you can run any task by adding a run command like the following.
name: stable-diffusion
resources:
clusters: aws-uw2
accelerators: v100:1
image: quay.io/vessl-ai/ngc-pytorch-kernel:22.12-py3–202301160809
run:
command: |
python --versionWorking with the code and dataset
You can mount codebases or volumes to the container you created above simply by referencing volumes. Since we are using the Hugging Face Diffusers library in this tutorial, we will only mount our GitHub repo but you can also bring your own cloud or local dataset to build upon our app.
volumes:
/root/examples: git://github.com/vessl-ai/examples # mount codebase
# You can also bring your own dataset from S3, NFS, hostpath, etc.
# /input/data: s3://{bucketName}/{path}With our code mounted, we can now define our run command that will be executed as the container runs. Here we will set our default working directory, install additional libraries as defined in setup.sh, and finally launch the app by running main.py.
run:
- workdir: /root/examples/
command: |
cd stable-diffusion
bash ./setup.sh
streamlit run main.pyOur main.py file contains the model from the StableDiffusionPipeline library from Hugging Face and the simple web interface built with Streamlit. Here, you can see how easy it is to build an app that receives a text from the user and returns images or texts using Streamlit. You can use the following code as a basis for any prompt-based web application.
col1, col2 = st.columns(2)
with col1:
st.header("Prompt")
with st.form("prompt", clear_on_submit=False):
prompt = st.text_area("Enter your prompt here")
submit_button = st.form_submit_button(label="Generate")
with col2:
st.header("Image")
if submit_button:
image = pipe(prompt).images[0]
if submit_button:
st.image(image)Deploying the app
The last step in our YAML is to set up deployment options for our app. We’ll set the runtime hours and open up a port for the container. The interactive field provides multiple ways to interact with the container such as through JupyterLab, SSH, or custom services via specified ports.
interactive:
runtime: 24h
ports:
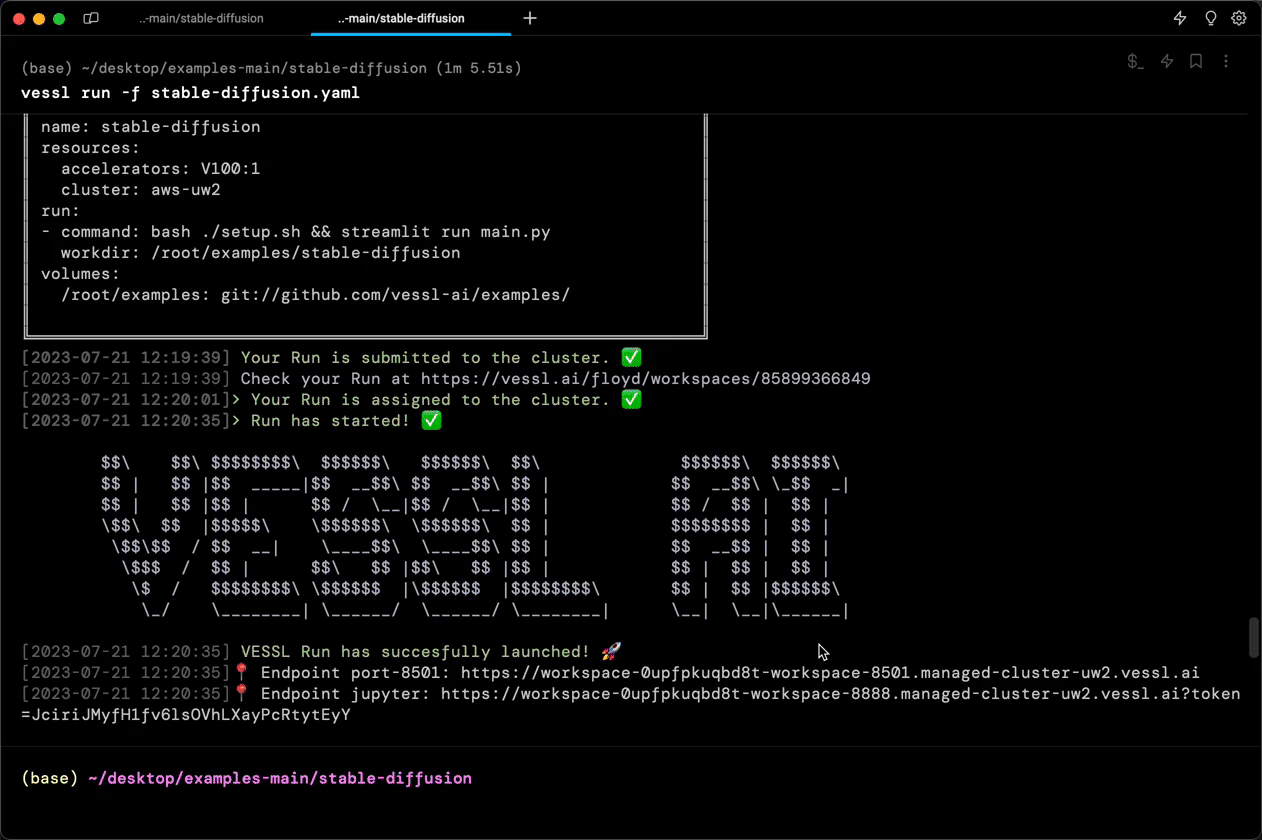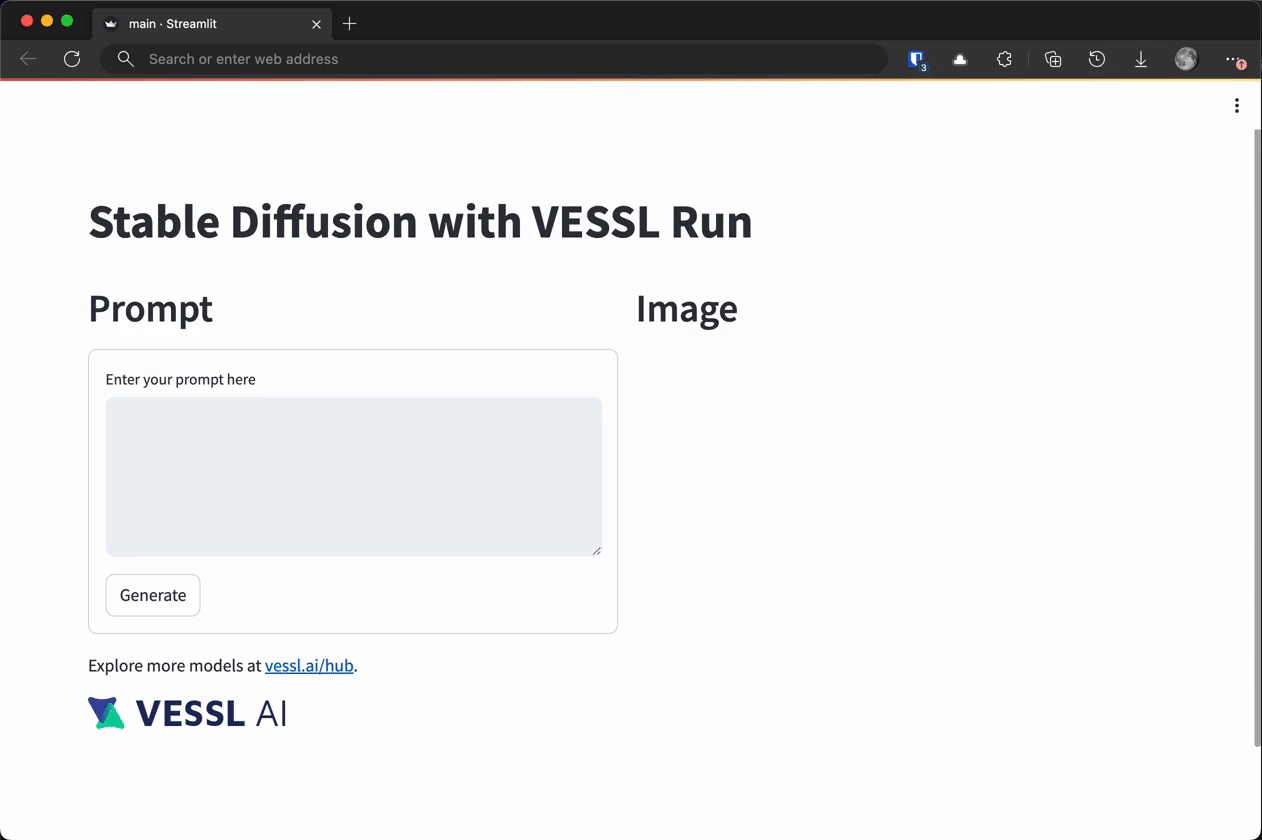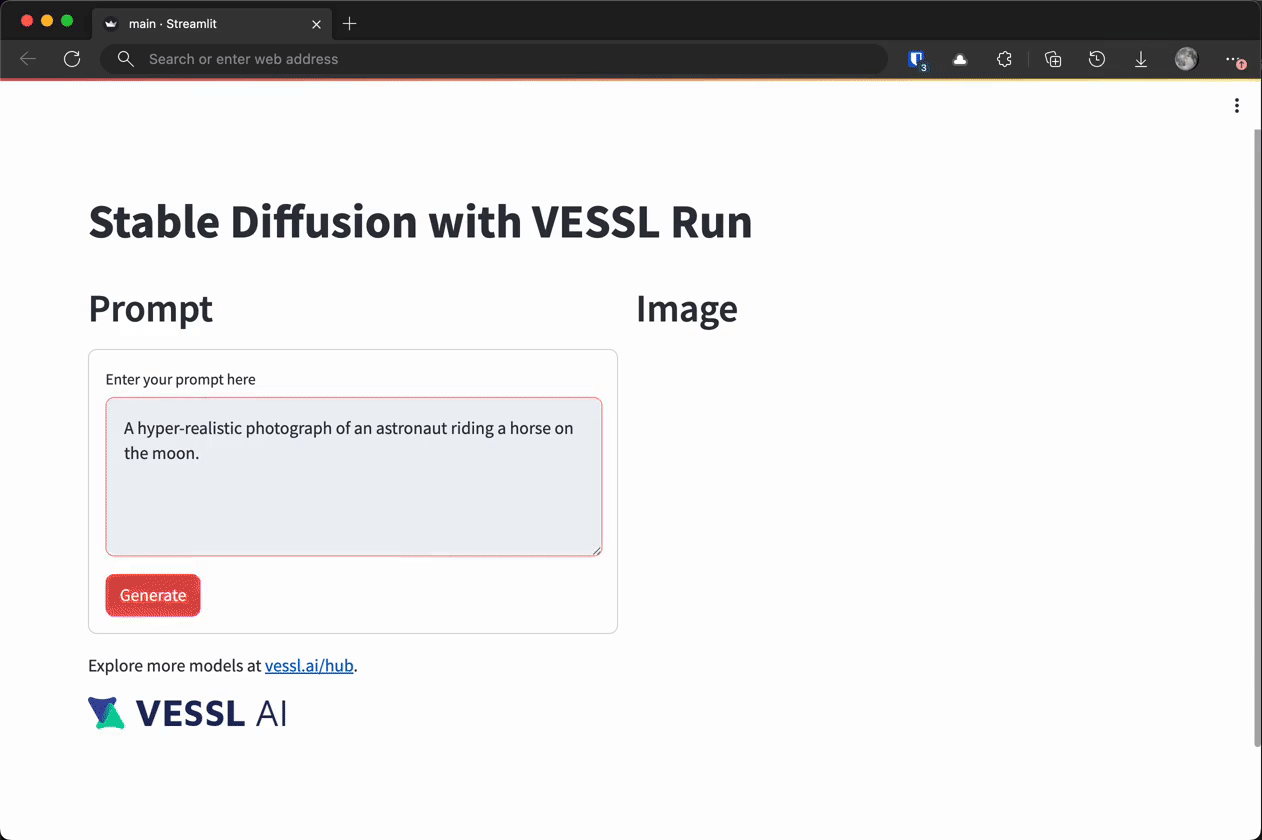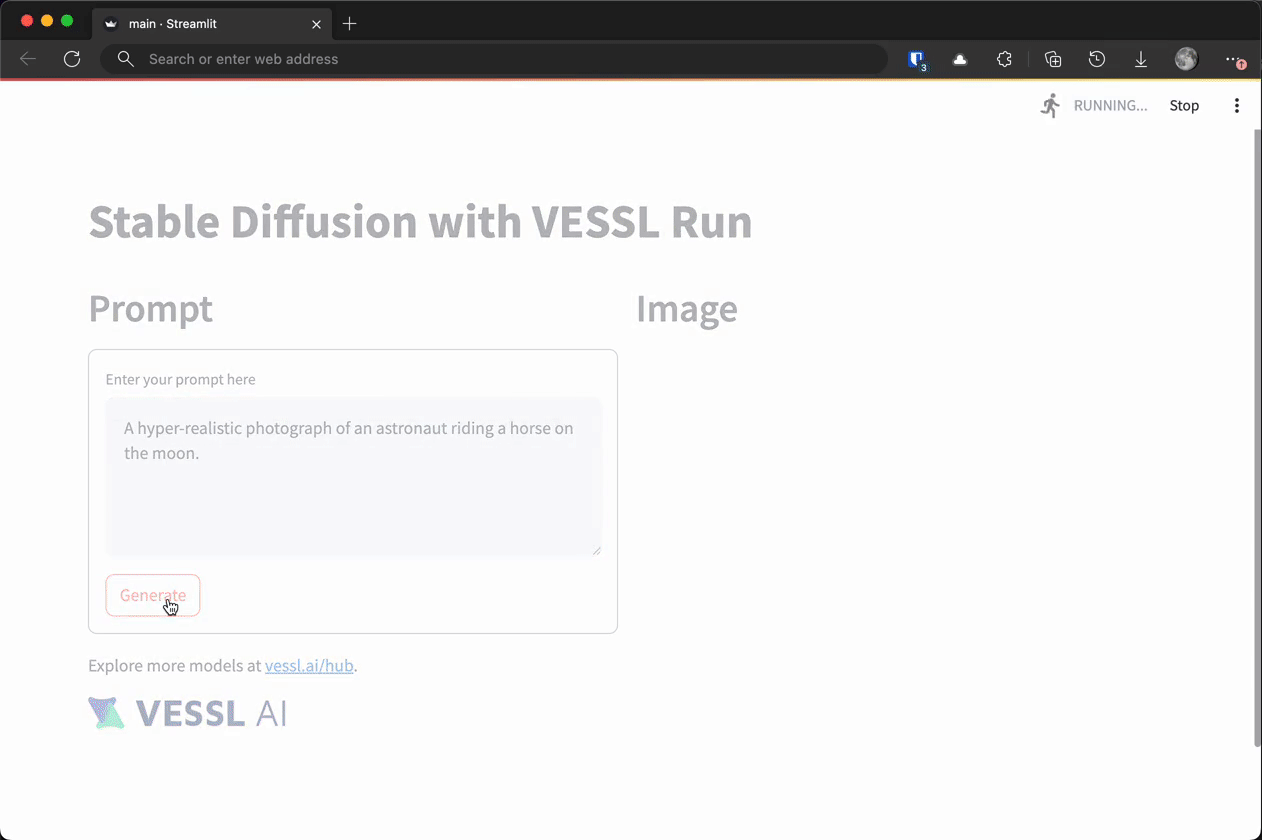
- 8501We can now run the completed YAML file using the vessl run. It may take a few minutes to get an instance assigned from AWS.
vessl run -f stable-diffusion.yamlThe command reads the YAML file and
- Spins up a GPU-accelerated Kubernetes on managed AWS.
- Sets the runtime environment for the model using Docker.
- Mounts a GitHub repo and storage volume.
- Executes run commands and launch the app.
- Enables a port for the app.
You can see the app in action by following the URL and entering a prompt.
What’s next
In this tutorial, we explore how you can use VESSL Run along with Hugging Face Diffusers and Streamlit to quickly spin up a GPU-backed AI application. Here, we used VESSL Run to set up the infrastructure layer for deploying models. You can use VESSL’s same unified YAML interface to train and fine-tune models simply by adding key-value declarations.
We prepared additional resources at our model hub where you can learn how you can also use VESSL Run to train and fine-tune the latest open-source models.
- Deploying Meta’s Segment Anything clone on the cloud
- Fine-tuning Google’s Dreambooth with Stable Diffusion
- Training an Image Animation model from CVPR 2023 Highlights
If you haven’t already, make sure to sign up for a free VESSL account so you can follow along. If you have any additional questions or requests for future tutorials, let us know by contacting us at support@vessl.ai.
—
Yong Hee Lee, Growth Manager
David Oh, ML Engineer Intern
